
Some still think telemetry is a futuristic concept, but it isn’t. It’s already integral to the smooth running of everything from websites, e-commerce platforms and mobile apps to manufacturing, traffic control and much, much more. And it all begins with the humble data log.
From the earliest days of computing, programmers have recorded useful information — often in a file — to help track and react to potential threats and understand what’s going on "under the hood" of their IT infrastructures. So, data logs, in one way or another, have been an innate part of troubleshooting software since day one.
However, telemetry really came into focus in the 1980s with the syslog protocol. This introduced the concept of structured logging and log routing via a network. And in 2001, it became the standard (RFC 3164 - The BSD syslog protocol) for log formatting and management. Since then, telemetry logging has been inextricably linked with applications and hardware systems, and it looks vastly different now compared to how it looked back in the early 2000s.
What began life as simple time-stamped, syslog-style messages has grown to encompass a much broader landscape of telemetry. This includes structured logs — for example, JSON and XML — dynamic metrics, and software debugging traces.
Data volume versus telemetry management
Telemetry now underpins everything from real-time systems monitoring and performance optimization to security, threat detection, and compliance. And along with any rapid technological evolution comes the matter of scale.
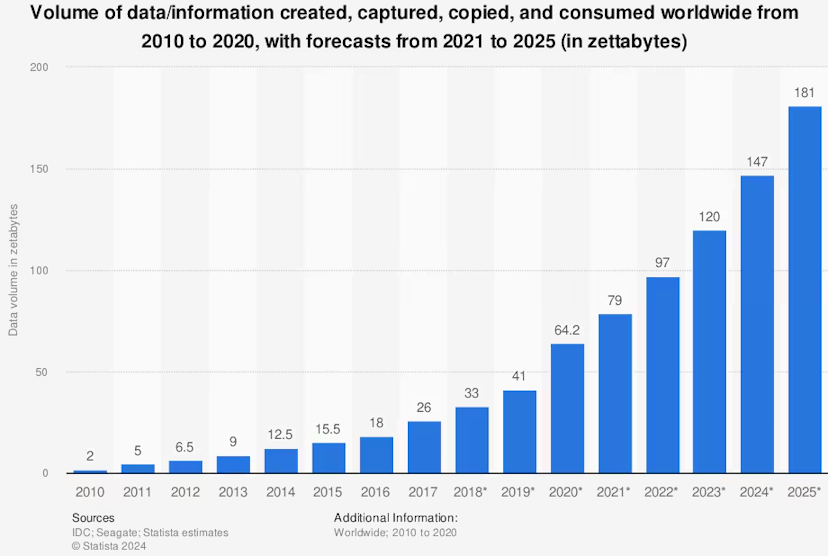
Data volume, including telemetry, has been growing exponentially, leaving many organizations grappling with how to manage it effectively. This massive data expansion has implications not only for storage but also for data collection pipelines.
The more data sources you have across an IT infrastructure, the bigger the data volume and the more diverse data formats you will need to process and route on the fly. These are all things a pipeline should be handling. So, why are many organizations struggling?
We could start by asking what the average data pipeline looks like in today’s businesses. Well, that depends on who you’re talking to. If you ask an IT or security team, they’ll describe a different system for log collection and management than the system DevOps engineers use to collect traces. Different job title, different data pipeline.
Unfortunately, this doesn’t work at scale. Having separate strategies and tools to handle telemetry in ever-so-slightly different ways, depending on what job you do, adds chaos to an already heavily data-burdened organization. Which brings us to the telemetry pipeline: a not yet fully adopted solution for collecting and managing logs, metrics, and data traces — at scale and in a unified way.
Telemetry pipelines are still relatively new to the market, and many customers don’t understand what they can bring to their business. So, they continue to struggle with legacy log management architectures that haemorrhage money because they don’t comply with regulations, can’t filter out unnecessary data, and can’t integrate well with other systems.
Telemetry Pulse report
When we attended the Cloud & Cyber Security Expo we took the opportunity to survey and interview almost 100 conference participants to dive deeper into how their organizations are handling telemetry.
We asked about their current approach to telemetry management and what’s holding them back. The results revealed some key trends and persistent pain points shared among participants but also critical opportunities for improvement.
- Telemetry is rarely collected at scale
-
Telemetry data is essential for operations and security, but 35% of organizations still don’t collect it at scale, exposing a growing gap in the coverage of failure detection and security analysis.
- Lack of telemetry data leads to compliance risks and operational losses
-
Failures in telemetry data collection create a cascading impact, threatening compliance and eroding operational response with missed or excessive security alerts.
- Legacy log collection is costly and outdated
-
Log data collection is now longer enough. It’s often ineffective, complex, and too costly to produce real value to organizations. This means modernization is both needed and urgent.
- Telemetry gaps create critical problems
-
Telemetry blind spots are widespread, putting operations, security and compliance at risk.
- Rising data volumes require telemetry pipelines
-
Spiraling telemetry data volumes greatly influence costs, and organizations are moving to telemetry pipelines to ease the burden.
- Organizations haven’t caught up to telemetry pipelines huge cost reduction potential
-
Telemetry pipeline solutions, with a smart pricing model and noise reduction technologies, can reduce costs by more than 50%. Most organization, even those that recognize the value of telemetry pipelines, haven’t fully realized the potential cost impact of this technology paradigm shift.
- Legacy data pipelines struggle from collection to decision
-
Data pipelines based on legacy tools are tearing at the seams, with inefficiency, blind spots and complexity. Teams working throughout the pipeline struggle across the entire data lifecycle, from collection to decision-making.
- Unified telemetry agent fix the legacy approach issues
-
Data collection agent fleets are often fragmented, creating architectural misalignment and unnecessary complexity. Organizations need unified, flexible and cross-platform agent strategies to fight these issues.
- Fragmented pipelines compromise security efforts
-
Encryption must be enforced at every stage of the telemetry pipeline, as security is now a crucial requirement and priority. This effort is considerably more difficult to implement and maintain in fragmented architectures.
Read the full report for a detailed look at these impactful insights that might change the way you think about telemetry and help you future-proof your telemetry strategy.